

A thought experiment on vibe-coding and the future of personal computing


Let me first state up front that this is not a post to make a case for or against vibe coding. In my mind, the cat is already out of the bag. Vibe-coding is here to stay, like it or not. The question is, where will things end up? In this post, I conduct a little thought experiment of a potential future world where vibe-coding continues to exist and what that might signify for personal computing.
As with all thought experiments, this post says nothing about the plausibility of such a world materialising within any given time horizon (although I think that the future imagined here is actually not that far away) and it will emphasis certain aspects of the dynamics while downplaying others. If you are still interested, read on…
Let’s start with some definitions…
I asked Gemini for a concise definition of vibe-coding and personal computing. Its responses are quite reasonable from my point of view. So here they are…
Personal computing is the use of a general-purpose computer designed for direct, individual control by one person. The devices, such as desktops, laptops, tablets, and smartphones, allow a single end-user to execute various tasks and applications without requiring a centralised operator or time-sharing with other users.
— Google Gemini 2.5 Flash
Vibe coding is an AI-assisted software development approach where a user generates functional code by providing natural language prompts and high-level descriptions to a Large Language Model (LLM) or AI agent, often with minimal or no direct review of the generated code.
— Google Gemini 2.5 Flash
These are the definitions that I will be going with in this post. Note the bolded parts, we’ll come back to them later.
The incompatibility of vibe-coding with the current software delivery model
There has been a myriad of complaints about vibe-coding. Many of them revolve around the consistency and robustness of AI generated code. Some of them are true. Some are due to the injured pride of software developers. Some of them will be remediated as AI gets better. Some are due to the fundamental flaws of Large Language Models (LLMs) as a “next-token generation engine”.
However, if we look beyond the surface of the complaints, one of the key source of these complaints about robustness are due to our current model of software delivery, which takes two main forms: Software-as-a-Service (SaaS) and Software-as-a-Product (SaaP).
In SaaS, a software provider builds the software and users access the software via a common portal. An example is Gmail. In SaaP, a software provider builds teh software and delivers it to user devices. Examples include Adobe Photoshop or Microsoft Office. Of course, these are two end of a spectrum. There are a million shades of grey in-between, like how Google develops a Gmail app and it is being used on users’ phones or how Microsoft allows for on-premise deployment of its SaaS products.
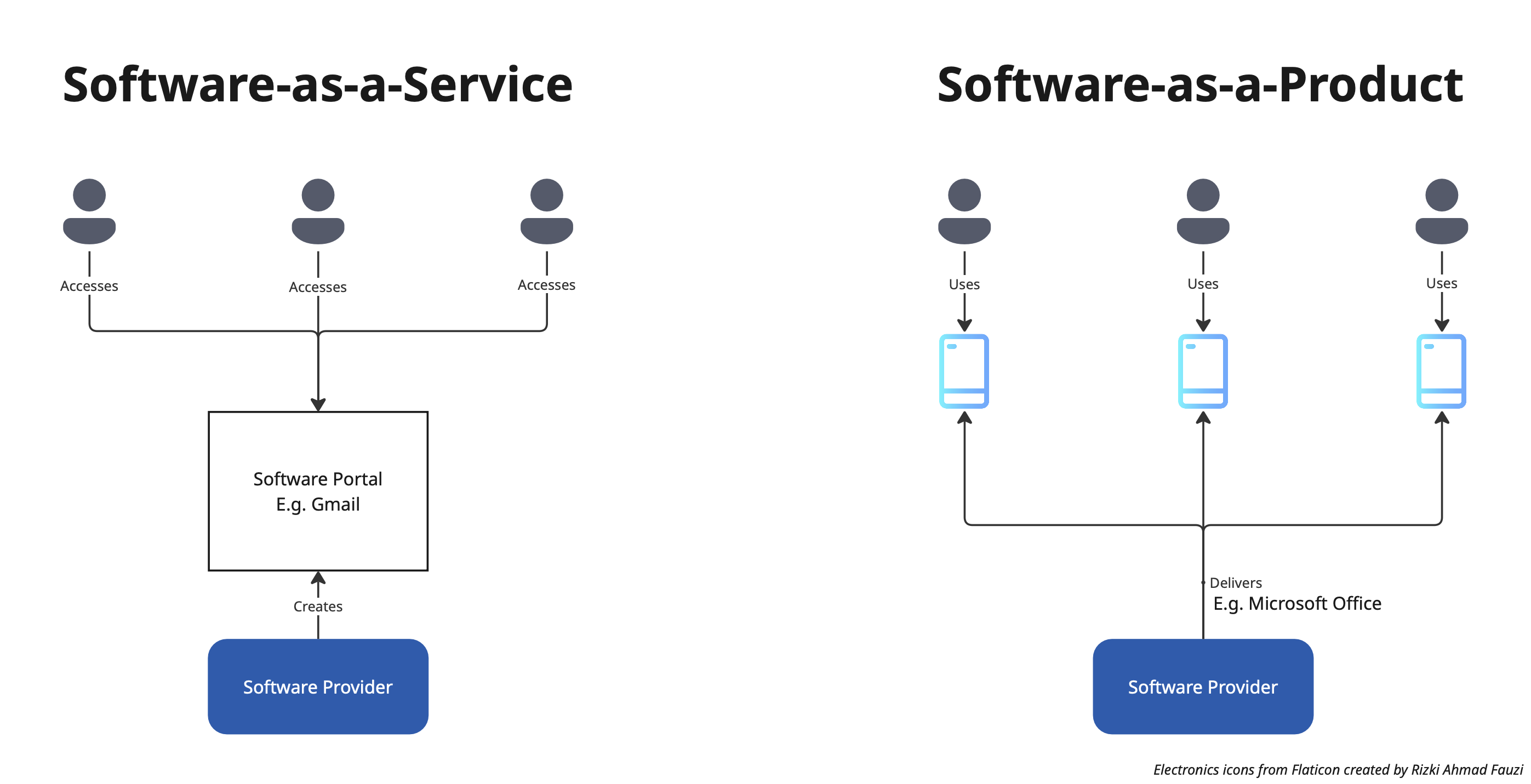
Either way, users interact directly with the software that is being built by the software provider. The users conform to the way the software provider has decided how the software functionality is to be delivered. Moreover, each software functionality is confined within the software product built.
In this way, the complaints around the lack of robustness of code generated by AI is well-justified (for now). After all, if the software provider vibe-coded and delivered the software with massive flaws to users, the blast-radius would be huge. Any security flaw, once exploited, could expose millions of users.
But what if the paradigm for software delivery changes?
A potential future: Software-as-Tools and N=1 Software
Let us now imagine that all user interactions with software is now intermediated by autonomous agents. After all, as I mentioned in my previous post, the real change that the GenAI revolution has brought about is a paradigm shift in the man-machine interface.
Users will all vibe-code. They will simply tell the autonomous agents what they want, and the agents will flexibly select the specific functionality they require to meet their users’ demands — meeting the definition of vibe-coding. Recall that currently, software functionality from a user’s perspective is “boxed” up in particular software applications. Yes, software providers have provided APIs for other developers to access fine-grained functionalities and compose those functions into other applications. But this fine-grained access is currently mostly limited to software developers — most of the world population aren’t software developers. If we look again at the definition of personal computing, we will see that being able to access fine-grained functions via API would not constitute “direct, individual control by one person” or personal computing.
The agents will develop N=1 software to do what the users need at that moment. The agents will take the fine-grained functionalities provided by software providers to construct dashboards, infographics, websites, micro-apps, etc. for the user on the spot. This presentation of information and performance of action will be for the user only, hence “N=1 software”. From this vantage point, the lack of robustness of software becomes less of a concern, since there is only 1 user. What we now think of as software prototypes/demos will in fact become the user application (if the word “application” still means anything) in the future.
Software providers will no longer take care of end-to-end user journeys. Software providers will simply provide small piece-meal functions, which in today’s agentic AI parlance are called tools, to be consumed by autonomous agents. Software providers as we know them today will retreat into the background just like how IT networking has retreated into the background of web-application development. This is where software development practices will continue to live on.
Requisite Conditions
I know that even at the time of writing, we are already able to catch glimpses of the future proposed above. More and more software providers are providing Model Context Protocol (MCP) interfaces to be used by AI agents. However, from what I can see, a lot of these functionalities are provided by a small set of companies and to a small set of users (usually software developers or very tech savvy people). In order for the above scenario to materialise in the mainstream, I believe a set of additional conditions need to be satisfied.
A trust mechanism for software
In the new world described, one can no longer say, “XYZ company was at fault for not taking care of this or that thing that caused me to lose money/get scammed/not be able to get my stuff on time, etc.”. Everyone in fact becomes a producer of software of sorts. Everyone is like a chef (or rather everyone has a chef) that takes raw ingredients (tools) and makes a dish to the person’s liking (N=1 software). If something goes wrong, then do we know if it is the ingredient that is at fault? Or is the chef (AI agent) a bad chef?
One way to circumvent this problem is to have all software tools openly reviewed and scanned reviewed by an independent (or maybe decentralised) body and the results published on a decentralised ledger. The execution of the code should then reference a repository where the code version/provenance could be transparently reviewed. On the point of transparent execution of code, the reader might want to check out the Unison programming language on content-addressed code.
Smaller models capable of running on personal devices
Going back to the analogy of AI agents being personal chefs, an underlying point about that is that the personal chef knows your personal likes/dislikes. In the case of N=1 software, it would be knowing what’s the best way to present information so that you can consume it easily, knowing your intellectual blind spots and taking the effort to help you cover them or understanding what you might be interested it given what your recent experiences. This cannot happen if everyone is using AI models that are designed for everyone else as well.
My personal take is that the current transformer-based large AI models will not be the paradigm that takes us into the age where AI is ubiquitous. There should be a different AI approach, perhaps something like the Tiny Recursive Model (TRM) combined with modular AI (see below).
Modular AI
Just like how software development went from monolithic applications to modularised plug-and-play libraries, the same could happen to AI. In the new world of personal computing, there is a need for access to knowledge (via large models, like how the internet has Wikipedia), personalisation (via small local models) and actuation (via tools). All three can be built and owned by different parties. All three are required for AI to fulfil its full promise for individuals, in my opinion.
For that to happen, the current way of running AI models has to change. AI models have to be reconfigurable and be able to “hot-swap” modules. Say I have an LLM that has general knowledge and the ability to “speak”. Now I want to inject embeddings that encodes my preferences or add in a new sensing modality like the ability to “see”, there should be a way to do it. Or it may even be the other way around where the LLM simply provides the embeddings and everything is orchestrated locally by my personal model.
Now, if any of the models change, for example the embedding size changes, how will the other models cope with it? Currently, the way this is overcome, by virtue of the advent of LLMs, is via natural text. Like how LLMs choose which tools to use. But natural language is a very low bandwidth way of communicating information and what happens if it is visual information? If the information to be conveyed cannot be conveyed as text, then the current way of communicating is via actual neural network layers that are run on the same chip (or in the same AI model).
To this, I do not have an answer yet.
Decentralised ownership of AI models and storage of personal data
Together with the point above, there will be a need to store the personalised models and data in a decentralised manner. This could perhaps again be achieved via a decentralised ledger, where everyone owns their own data which is used to train their own model (the personal “chef” or AI agent) and is only accessible by the individual.
Of course, there is no guarantee that such a decentralised ownership model will materialise. If we look at what is happening now, the large AI models, by virtue of their size, are owned by large corporations. Those same corporations also happen to be in control of our data. However, I cannot imagine this to be good if AI were to become ubiquitous and the power these companies will wield over society.
Widespread support for provision of services via agents
This goes without saying, for the “N=1 software” future to become reality, more service providers need to provide their services as tools. I’m not just talking about those names that you wouldn’t be surprised to see in Silicon Valley or tech startups claiming that they would revolutionise the world. I’m talking about everyday services like restaurants, plumbers, etc.. Because having to jump between the old (phones, websites, apps) and new way (AI agents) of doing things simply won’t lower the inertia of change that people have. This tells me that that future may not come as soon as tech billionaires want us to think.
What does it mean?
General public
For the general public, as I’ve said before, this means that the way humans interact with machines/software will complete change. Everyone will have their own personalised view of things (whether that is socially desirable is another question). On top of that, everyone will need “people” management/communication skills. The reason why I say this is because anyone who is using AI agents extensively now will realise that dealing with AI agents is very much like dealing with a person. And the better your communication skills are, the better you can get things done with AI agents.
Software developers
As for software developers, I actually don’t think that this will be the end of software development. Just like how many computing-related activities such as networking, sort of retreated into the background, so will software development as we currently know it. Software developers will still be required to develop tools, which are the fine-grained functionality that probably requires software development rigour. Of course, the skillset involved will be very different from today and it will also be AI-assisted.
There will be also be other areas that require software engineering that will grow, such as in decentralised ledgers (see later section).
Service providers (Sellers)
Service providers (or software providers) will also have to get used to a very different world. Think Uber which takes care of the end-to-end user journey of getting people from point A to point B. You book a ride, see when your ride is arriving, pay, lodge complaints, etc., all in one app. And that user journey is designed and engineered by one company with a particular philosophy or approach.
In the new world, service providers not only need to deal with the fact that there will no longer be a consistent representation of their services to the end-user, they also need to contend with the fact that there is an additional layer of mediation which is the AI agents between them and their users. This is true regardless of whether the AI agents are owned by large corporations or individuals. The result of this is that service providers will be “out of sight-out of mind” for their customers. Just like how when AliPay or WeChat became the default mode of payment in China, Chinese banks only saw 2 transactions each month from their customers: one when the salary came in and another when the salary got transferred to AliPay/WeChat. This means that they will no longer be able to influence their customers or lock them in like they can now.
Decentralised ledgers / Blockchains
With the advent of generative and Agentic AI, the need for proof of authenticity is never higher. And as mentioned before, decentralised ownership and storage of personal data might require a mechanism like a decentralised ledger. Maybe there are other ways to do this, but for now blockchains seem like a good candidate to store model certifications and ownership proofs.
New economy of tool aggregators and AI trainers
This new world of personal computing will also spawn new economies of tool aggregators and AI trainers. Just like how the internet age brought us AirBnB and Bookings.com, the new world will have its own aggregators for AI agents to discover new tools.
There will also be AI trainers to help people train their personal AI. Or maybe even AI trainers that train specialised AI agents that can be replicated infinitely to anyone who needs a specialised task done. For example, a 10x software developer in Rust could train an AI agent that codes as well as he/she does. Put it on the blockchain and market it via one of the tool aggregators.
Taking into account radical uncertainty
The impact of AI on personal computing expressed here is by no means exhaustive and certain (remember, this is only a thought experiment). To borrow the term radical uncertainty by Mervyn King, there are many unknown unknowns for which we cannot “price” in the effects that they might have.
Conclusion
This is a thought experiment on how the future of computing will look like in the age of AI. I do not purport that the world proposed is a plausible one, only a possible one. And for sure, there are certain elements that are far-fetched, certain elements oversimplified and certain elements that would require fundamental changes that are harder to come by than I can imagine. But I do believe that some aspects of this new world will materialise in the very near future and it is rather exciting to think about it.