

CodeWalkthrough: Deep Learning in Scala using Storch and fs2
Functional deep learning on GPUs in Scala

I fell in love with the expressiveness, type-safety and support for functional programming of Scala but the Scala ecosystem when it comes to Machine Learning (ML) is quite a bit behind that of Python (to be fair, it’s hard to find an ML ecosystem that can rival Python’s). So I was pleasantly surprised when I stumbled Storch, a Scala deep learning library based on LibTorch with the ever-familiar PyTorch API. This allows me to potentially do my deep learning experiments in Scala.
Separately, I was inspired by a talk by Fabio Labella that talked about using fs2, a library for coding “functional, effectful, concurrent streams in Scala”. This gave me an idea to try and apply an asynchronous, stream-based way of coding to the AI model training process.
In this article, I’ll walk you through my experiment on using fs2 and Cats Effect to string together the various steps in a basic AI model training. I encourage you to clone the repo to follow along.
A little on fs2 and Cats Effect
Cats effect and fs2 are two key libraries in the typelevel ecosystem that enables functional programming in Scala.
Cats effect implements an asynchronous runtime in Scala via the IO object as well as typeclasses such as Ref, which we will be using later to maintain shared states.
fs2 is a stream library that is widely used to manage complicated data streams. It relies on a key benefits that often comes out of functional programming: compositionality, which allows a process to be broken down into parts and seamlessly combined. It also implements primitives such as topics, queues and channels for more complex ways of combining data streams.
Side note: Personally, fs2 is one of the most amazing libraries I’ve come across. It’s super powerful and expressive. On top of that, the pull-based mechanism for streaming data allows constant-time processing, keeping compute resource usage manageable.
Setup
My aim here is to demonstrate the use of functional streams for deep learning with GPU on Scala. So I’ll be using an oldie-but-goodie, the MNIST digits classification, as a use case.
In this way, I can focus a little bit more on Storch and fs2.
Storch also conveniently provides an API to the MNIST dataset (like how PyTorch has an API for commonly used ML datasets) shown below (click here for link to code).

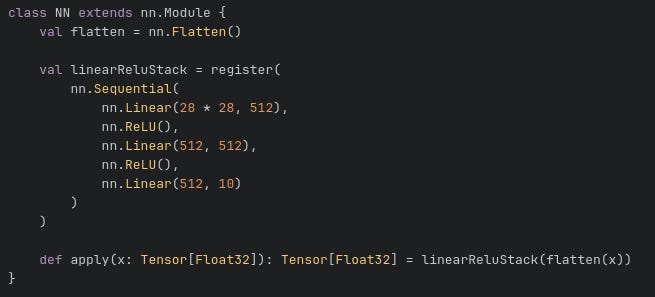
As mentioned, Storch implements the PyTorch API. The neural network used is a simple multilayer perceptron seen below. The syntax should be familiar to any PyTorch user.
Training step
fs2 works on the concept of Streams. For those who are not familiar, think of it as a river of data (or “1”s and “0”s) which keeps following until the program ends or the data is exhausted. Importantly, fs2 streams are pull-based. This means that data isn’t continuously fed from the input end but pulled in from the exit end of the stream.
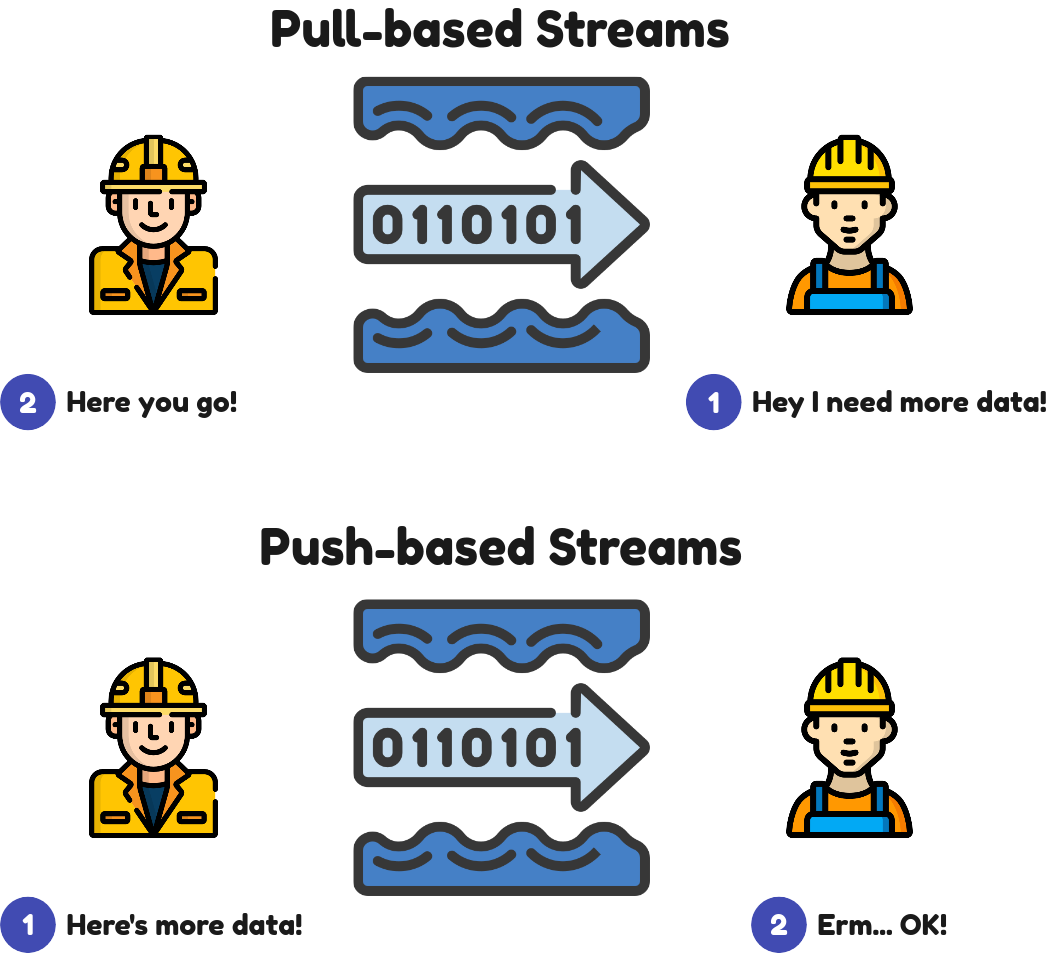
The nice thing about pull-based streams is that data is only delivered and computed just in time. Only when the consumer end requires the data will the data be delivered. Compare this to a push-based stream where data is delivered until either some queue is full or the consumer can no longer handle more computation, a pull-based stream means that the resource usage can be kept manageable.
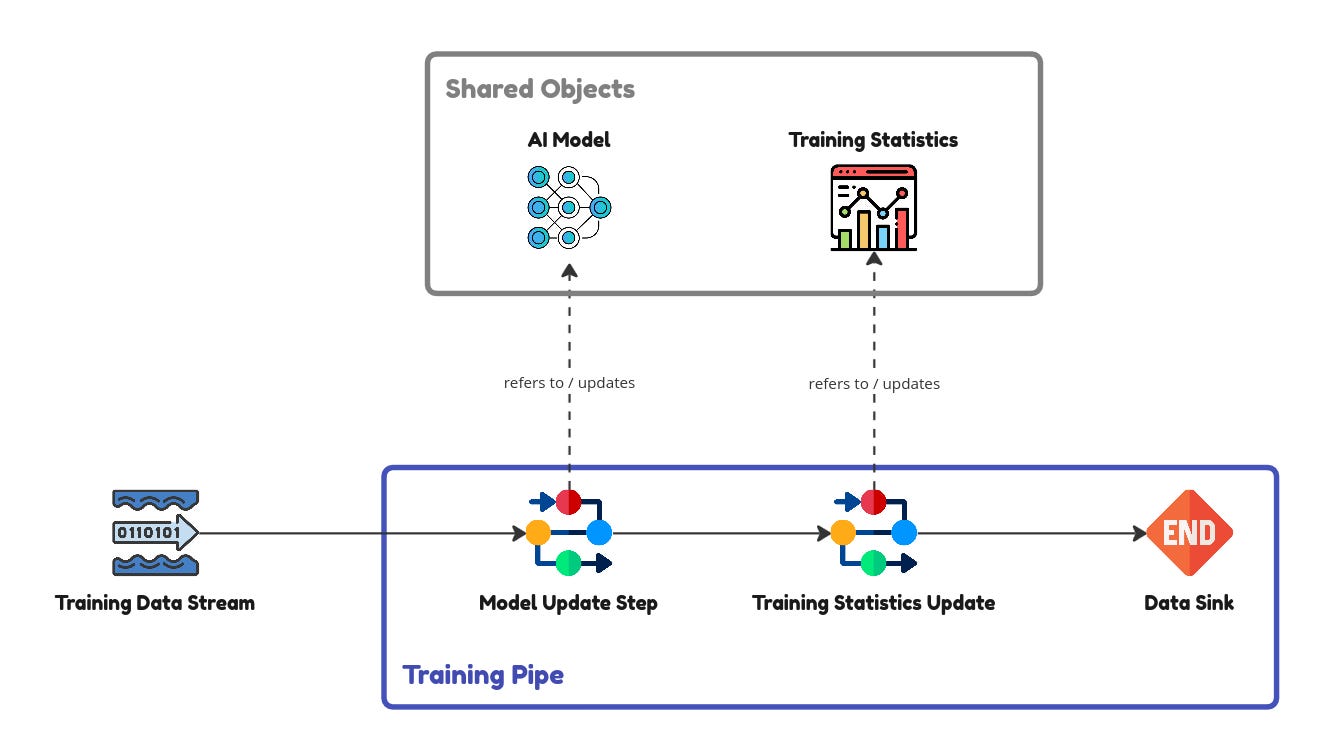
The training step of updating the model parameters by showing the model various batches of data can be seen below. The training data is delivered in batches via the training data stream on the left. Each batch is then put through the model update step which updates the model weights followed by the storing of the training statistics such as training cost. The AI model here is initiated as a shared object so that each batch of data updates the same model. The same goes for the training statistics. This proceeds until all the data in the training data stream is exhausted.
The code for the above is here. Note that the return type of Pipe[IO, Sample, Unit]. An fs2 pipe is a function that takes a stream of one type and transforms it into a stream of another type. In our case, Pipe[IO, Sample, Unit] is the same as Stream[IO, Sample] => Stream[IO, Unit]. It’s job is to perform the key model training steps for each batch of data. I won’t spend too much time dwelling on the syntax of fs2. Interested readers should read the documentation.
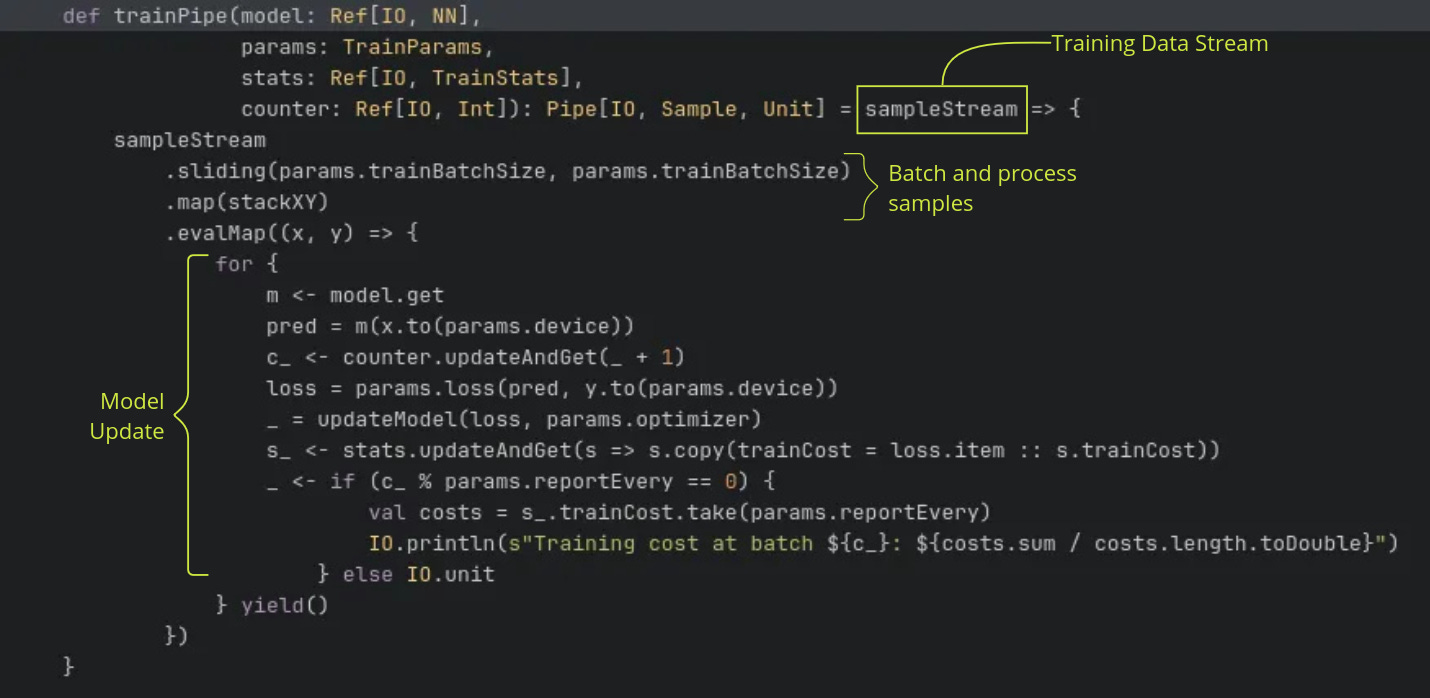
Taking a closer look, trainPipe takes in a sampleStream as input, this is the training data stream. The data is batched using sliding and stackXY reorganises each chunk of data into a tuple of inputs and targets. The key operations are in the evalMap section, where each batch of data is then mapped to the asynchronous function that updates the model and training statistics.
Note that the model (model) and training statistics (stats) such as are passed to trainPipe as Ref. Ref is a typeclass in Cats Effect that allows for shared states. This allows for the training and validation streams to refer to the same data objects.
Validation step
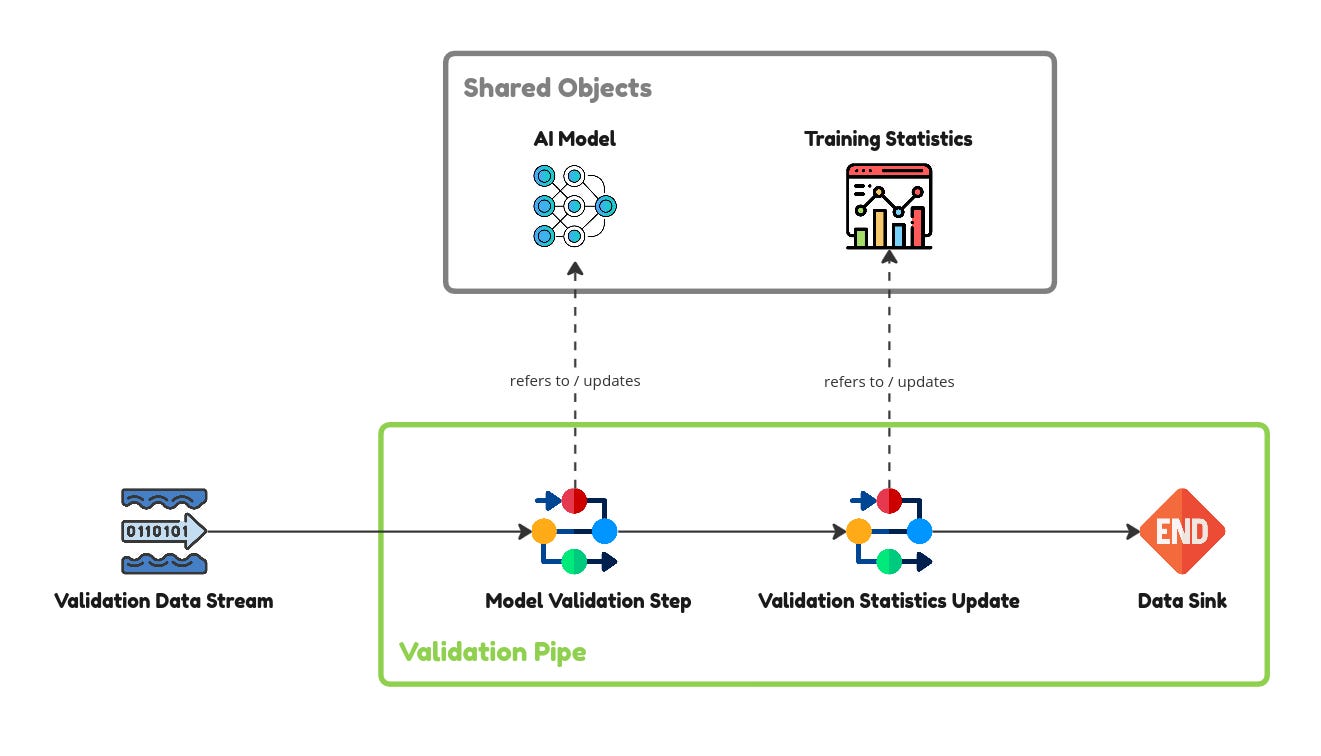
The validation step is coded similarly to the training step where there is a validation data stream fed to a pipe. See below (code here).
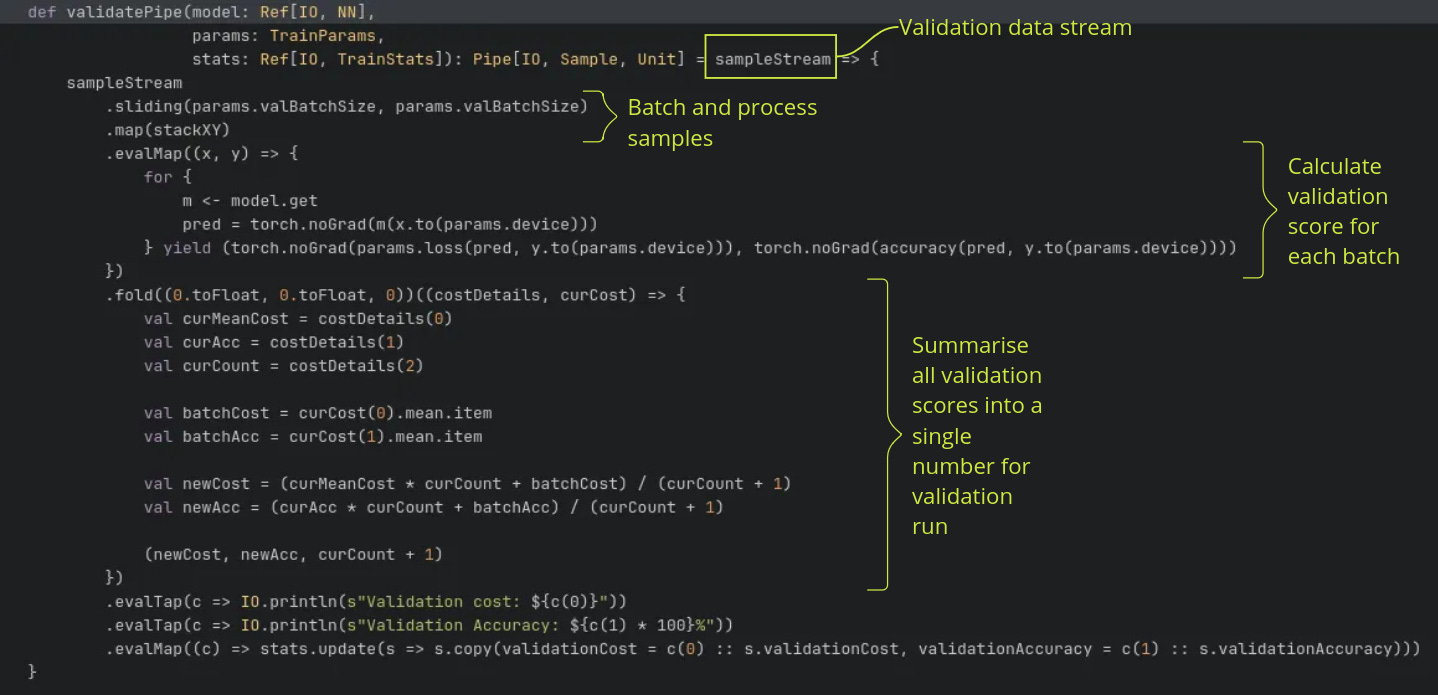
The key thing to note here is the fold method which accumulates all the results from the validation batches into a final validation cost and accuracy of the entire validation data stream. Since fs2 is built on Cats and Cats Effect, typeclasses like Applicative, Monad and Foldable are available. This enables semantics like fold and flatMap which opens up the expressiveness of the language.
Putting it all together
Now that we have each step of the training process in place, we need to put them together as follows.
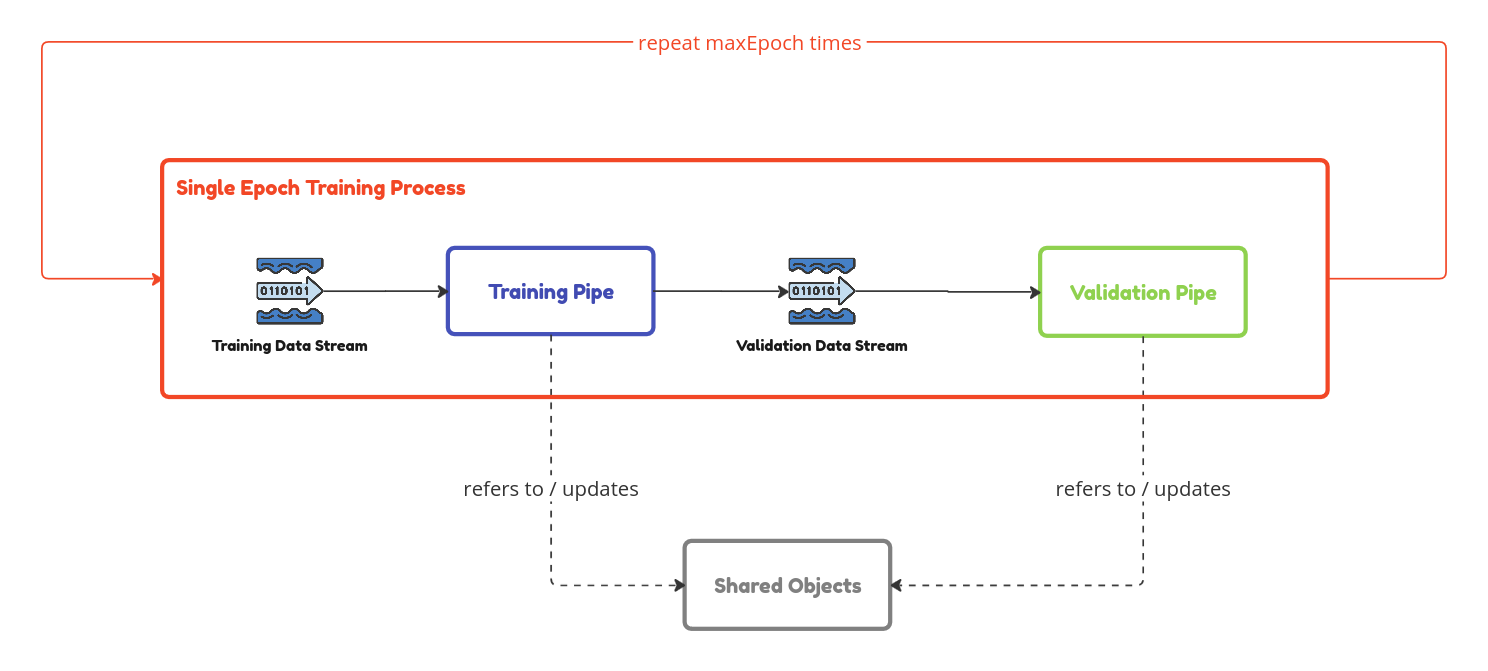
After each training and validation epoch, we need to repeat the process for a number of times. Now this is where fs2 with its functional programming roots really shine. One of the key benefits of functional programming is compositionality. I.e. we can create complex patterns by composing functions. This can be seen in the main run function here.
Taking a closer look, the loop is implemented simply as an append and repeat.

I can safely do this because of the semantics made available by fs2. I didn’t have to do any boilerplate to manipulate types or additional control flow.
One last thing… IOs…
You would have notices that the data type IO throughout this demo. IOs are a basic higher order data type from Cats Effect that allows for asynchronous computing. In a nutshell, what I’m doing when I’m instantiating the functions in my program is I’m collecting a series of instructions to be run at a later time. Kind of how Apache Spark collects the data processing instructions into a Directed Acyclic Graph (DAG) to be lazily evaluated later.
For those coming from an interpreted language like Python, myself included, this can take a little getting used to.
Final Thoughts
Out-of-memory datasets
In this demo, I had the MNIST dataset loaded in memory since it is small enough. But you can read data from files or databases in a stream-like fashion, keeping memory usage capped.
Complex training patterns with fs2 primitives
More complex model training patterns can also be enabled by fs2’s primitives. For example, training a model from various disparate data sources can be enabled with Queue. Or training multiple models concurrently from a single data source can be done via publish-subscribe with Topics.
Scala ML Ecosystem
While Scala has found widespread use on the data engineering scene (think Apache Spark and Apache Flink), libraries for numerical computing is generally lacking compared to Python. For example, Scala’s numpy equivalents like Breeze are not as actively maintained. Availability of graphing libraries like matplotlib for Python is also not very good. If I needed to do machine learning, Apache Spark is likely my best bet, but I don’t quite want to run a Spark clusters (even a local one) just to train a simple model.
Storch is a step in the right direction by introducing a Scala wrapper over LibTorch. It’s still not as fully featured as PyTorch but the support for tensors and autogradients offer an opportunity for numerical computation on both CPUs and GPUs.
Other nice things in the Scala ecosystem include:
Support of Scala kernel in Jupyter notebooks
Polynote, a Scala notebook which allows sharing data objects to Python for plotting
One thing that I thought would be a good idea is a Scala API for the Polars dataframe library.