

Experiment: Training multiple models on a single GPU
Satisfying my own curiosity on what happens when we run multiple model trainings on one GPU

I have a NVIDIA RTX A4500 GPU in my workstation with 20GB of video memory and was curious about what would happen if I try to train multiple models on it concurrently. So I did a small little experiment to find out. The code is here.
Subjectivity notice:
This is an experiment I conducted, with limited time and effort, to satisfy my own curiosity on what happens to model training times when you try to train multiple models concurrently. It is by no means a rigorous and complete study.
Experiment Process
I created a simple model training script based on the “Transfer Learning for Computer Vision Tutorial” on the PyTorch website
This is a simple use case with a very small dataset
I don’t really care about how well the model is training. What I care about is, how does the training times change when you have multiple model trainings running at the same time.
I used the pretrained ResNet50 model as my base model. It takes up around 1.25GB of video memory each. In this way, even if I run 10 of these, I would not max out my GPU memory.
I then built the training script into a small Python library called
tmsgThis allows me to simply install the model training script as a library in a Docker container
The Python library has a console script called
trainin order to quickly invoke the training process
After step 2, I built a Docker image with
tmsginstalledThe training script is invoked as the container entrypoint
Lastly the training epoch durations are recorded for n concurrent model trainings
n = 1, 2, 3, 4, 5.
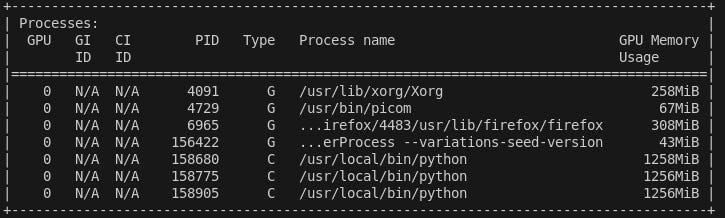
See screenshot below which shows the example of 3 concurrent model trainings, each taking 1.25GB of memory.
Each time, I made sure no other heavy process is running on my workstation
The training data fits into memory comfortably so that we are not repeatedly reading the files directly. This is so that we won’t have any bottlenecks due to disk reads by multiple concurrent processes.
Results
The training epoch durations are shown below.
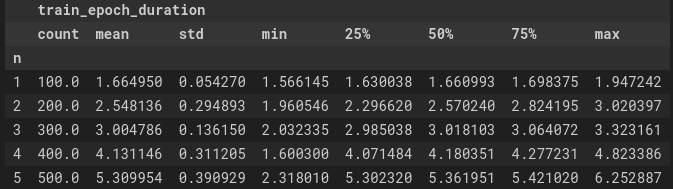
When only 1 model is being trained, each epoch took around 1.66s. However, with five concurrent model trainings, each epoch takes 5.3s on averge. Even though, the GPU memory was not completely utilised, the model training still slowed down. This is probably due to the fact that there is a bottleneck in multiple processes trying to transfer data to the GPU at the same time.
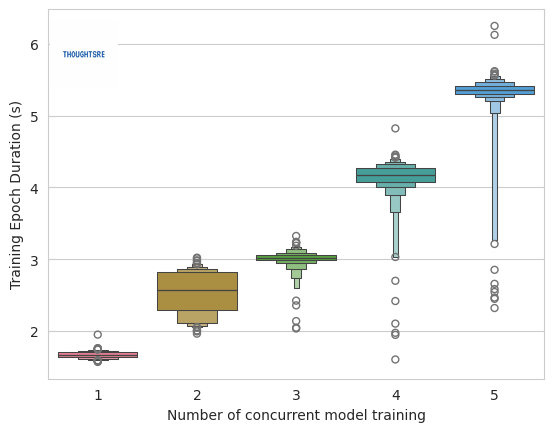
The graph above also shows the distribution of the epoch durations at various n values. Another thing I noticed is that the range in epoch durations increase with n. This is most likely due to the fact that during the starting and end phases of each run, we do not have all processes running. For example, when the model training is starting up for the second process, only the first process is running on the GPU and hence the epoch durations should be quite close to that of n=1.