

SuperGlue: An AI model for visual feature matching
Using AI to improve a fundamental process in Computer Vision

Feature matching between images is a process where correspondences between key points in disparate images is established. It enables one to understand how the view point containing an object in one image needs to be translated and rotated to achieve the view point in another image containing the same object but from a different perspective. It is a fundamental step in advance computer vision processes like image stitching and Structure-from-Motion (SfM).
In general, the greater number of matches that can be discovered between key points of two images, the better we can calculate the transformation matrices, such as the homography matrix or the fundamental matrix, that are needed to understand the perspective changes between the images.
This is why I was excited to try out SuperGlue, an AI model that helps you do feature matching, when I first heard about it. I was curious to find out whether it would do better than the traditional OpenCV methods I was using in my previous experiments.
The code for this experiment is here. It’s not very complicated. Most of the code using SuperGlue is that given on the HuggingFace website.
Overview
In this experiment, I compare the feature matching results from SuperGlue with that from an ORB feature detector + brute force matcher. As a demonstration, I have three simple test cases which I ran through both approaches.
A scene of an outdoor building. This is the demo picture from HuggingFace.
Two overlapping pictures of a mountain. This is taken from the University of Maryland CMSC426 course. I chose this as the mountain image contained rough textures that might be hard to match uniquely if you only look at local pixel features.
Cropped pictures of a pagoda at Mount Fuji. The pagoda has rich features from a human perspective and contains certain background features that might be useful to a human in matching the images. So I was wondering whether a machine can do the same.
For the OpenCV approach, I used sensible parameters that I found effective in my previous image stitching experiment.
Results
The matching results for the demo scene from Hugging Face is shown below. Not only were the number of matches found by SuperGlue is much greater than that by OpenCV, it also seems like the results by SuperGlue were more accurate. For example, the tip of the dome in the image on right was matched to the base of the dome in the image on the left by OpenCV.
For the SuperGlue results, green, yellow and red lines indicate a good, OK and not-so-good match, respectively.

The results for the mountain were similar. I was surprised by the number of matches found by SuperGlue. For a human it might be easy because we take in the entire picture and match points based on its relative position to key contextual features such as the peak of the mountain.

Again, the same for the mount Fuji test case. One thing that I found quite interesting as well is that SuperGlue managed to match the corners of the pagoda roof (indicated by the red squares). ORB was not able to match those features.

Reason behind SuperGlue’s effectiveness
Traditional methods such as ORB uses local features as key point descriptors. One can think of it as embeddings in today’s LLM parlance. These descriptors are often a simple function of the raw pixel values. For example, ORB uses the BRIEF descriptors, albeit with some additional machinery to account for feature rotation. Nonetheless, it is very much a description of the local environment of the keypoint in the image. And the matching of key points are based off these local descriptors.
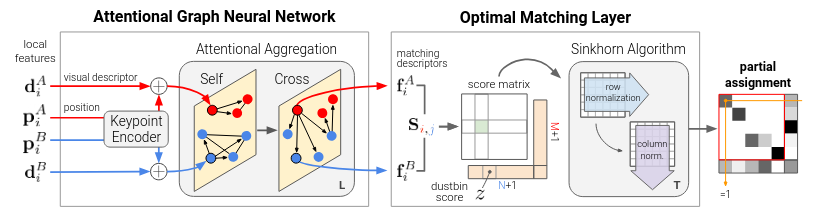
SuperGlue on the other hand, uses an attention graph neural network. This graph neural network not only connects the key points within each image but also key points from the other image. This allows contextual information from the rest of the image to be taken into account. And I believe this makes all the difference in performance. This is why the corners of the pagoda tower can be detected as it is able to understand how that key point is related to all the other key points in the images.
Final remarks
I was pleasantly surprised by the performance of SuperGlue and I can see how it can help boost the quality of the results of Computer Vision processes that depend on feature matching. I recall having issues calculating the homography matrix accurately due to a lack of matched keypoints, which then resulted in wildly distorted stitched images.
It is clear that using AI models in this way or maybe even multiple AI models in concert to replace previous methods of math/optimization-based calculations can potentially speed up many computationally heavy processes and can be very beneficial to many everyday processes.